README.md
| 1 | --- |
| 2 | license: mit |
| 3 | language: |
| 4 | - zh |
| 5 | - en |
| 6 | - fr |
| 7 | - es |
| 8 | - ru |
| 9 | - de |
| 10 | - ja |
| 11 | - ko |
| 12 | library_name: transformers |
| 13 | --- |
| 14 | |
| 15 | # GLM-OCR |
| 16 | |
| 17 | <div align="center"> |
| 18 | <img src=https://raw.githubusercontent.com/zai-org/GLM-OCR/refs/heads/main/resources/logo.svg width="40%"/> |
| 19 | </div> |
| 20 | <p align="center"> |
| 21 | 👋 Join our <a href="https://raw.githubusercontent.com/zai-org/GLM-OCR/refs/heads/main/resources/wechat.jpg" target="_blank">WeChat</a> and <a href="https://discord.gg/QR7SARHRxK" target="_blank">Discord</a> community |
| 22 | <br> |
| 23 | 📍 Use GLM-OCR's <a href="https://docs.z.ai/guides/vlm/glm-ocr" target="_blank">API</a> |
| 24 | <br> |
| 25 | 👉 <a href="https://github.com/zai-org/GLM-OCR" target="_blank">GLM-OCR SDK</a> Recommended |
| 26 | <br> |
| 27 | 📖 <a href="https://arxiv.org/abs/2603.10910" target="_blank"> Technical Report</a> |
| 28 | </p> |
| 29 | |
| 30 | |
| 31 | ## Introduction |
| 32 | |
| 33 | GLM-OCR is a multimodal OCR model for complex document understanding, built on the GLM-V encoder–decoder architecture. It introduces Multi-Token Prediction (MTP) loss and stable full-task reinforcement learning to improve training efficiency, recognition accuracy, and generalization. The model integrates the CogViT visual encoder pre-trained on large-scale image–text data, a lightweight cross-modal connector with efficient token downsampling, and a GLM-0.5B language decoder. Combined with a two-stage pipeline of layout analysis and parallel recognition based on PP-DocLayout-V3, GLM-OCR delivers robust and high-quality OCR performance across diverse document layouts. |
| 34 | |
| 35 | **Key Features** |
| 36 | |
| 37 | - **State-of-the-Art Performance**: Achieves a score of 94.62 on OmniDocBench V1.5, ranking #1 overall, and delivers state-of-the-art results across major document understanding benchmarks, including formula recognition, table recognition, and information extraction. |
| 38 | |
| 39 | - **Optimized for Real-World Scenarios**: Designed and optimized for practical business use cases, maintaining robust performance on complex tables, code-heavy documents, seals, and other challenging real-world layouts. |
| 40 | |
| 41 | - **Efficient Inference**: With only 0.9B parameters, GLM-OCR supports deployment via vLLM, SGLang, and Ollama, significantly reducing inference latency and compute cost, making it ideal for high-concurrency services and edge deployments. |
| 42 | |
| 43 | - **Easy to Use**: Fully open-sourced and equipped with a comprehensive [SDK](https://github.com/zai-org/GLM-OCR) and inference toolchain, offering simple installation, one-line invocation, and smooth integration into existing production pipelines. |
| 44 | |
| 45 | ## Performance |
| 46 | |
| 47 | - Document Parsing & Information Extraction |
| 48 | |
| 49 | 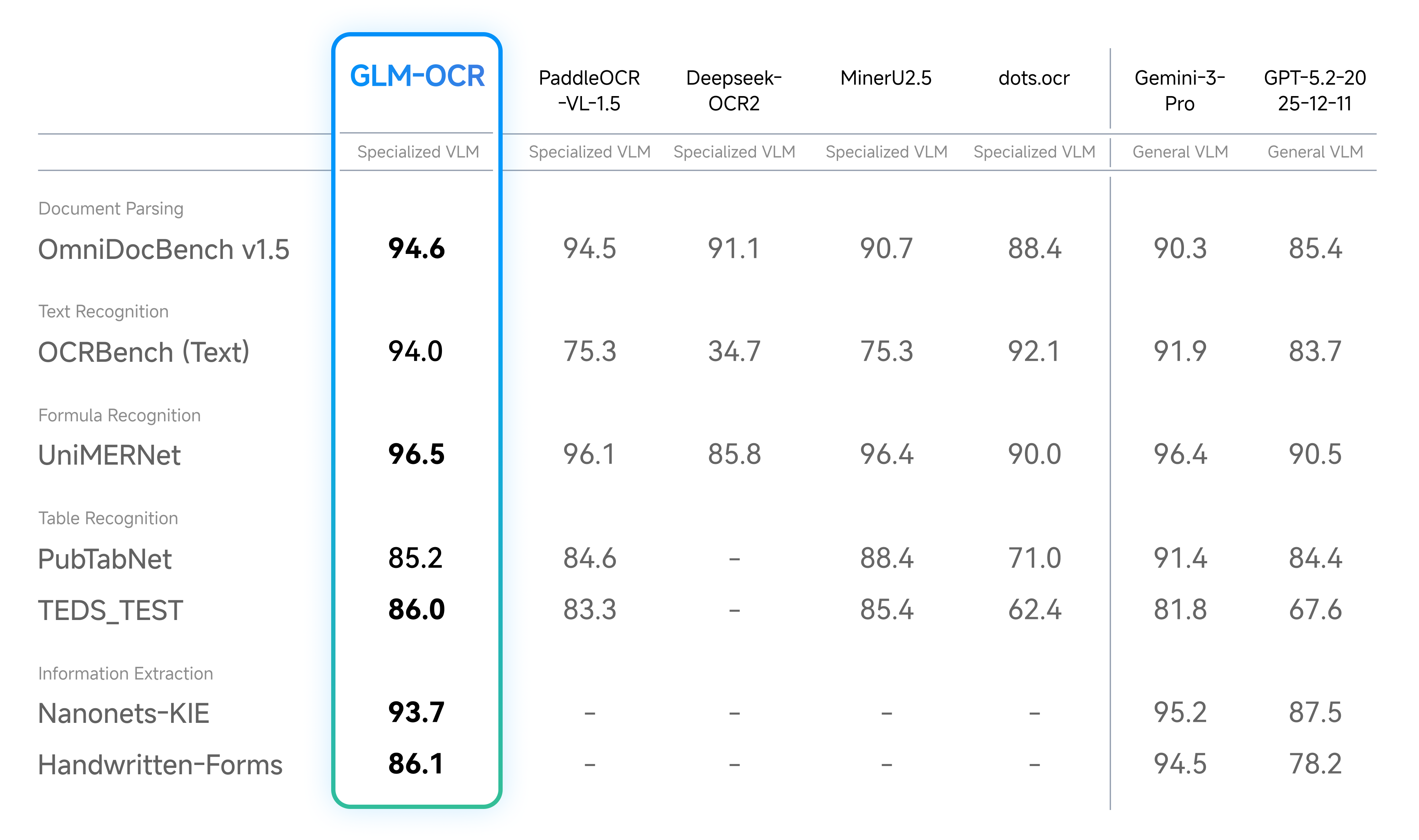 |
| 50 | |
| 51 | |
| 52 | - Real-World Scenarios Performance |
| 53 | |
| 54 | 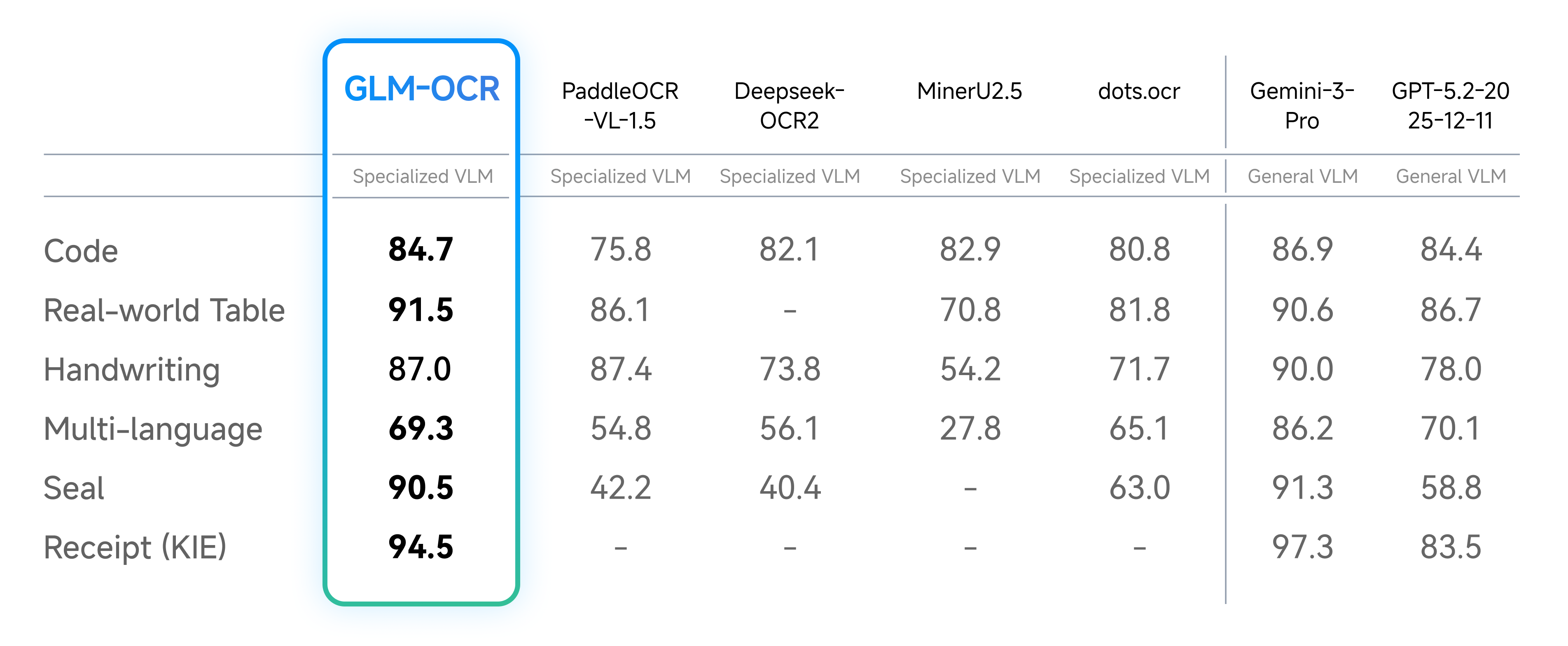 |
| 55 | |
| 56 | |
| 57 | - Speed Test |
| 58 | |
| 59 | For speed, we compared different OCR methods under identical hardware and testing conditions (single replica, single concurrency), evaluating their performance in parsing and exporting Markdown files from both image and PDF inputs. Results show GLM-OCR achieves a throughput of 1.86 pages/second for PDF documents and 0.67 images/second for images, significantly outperforming comparable models. |
| 60 | |
| 61 | 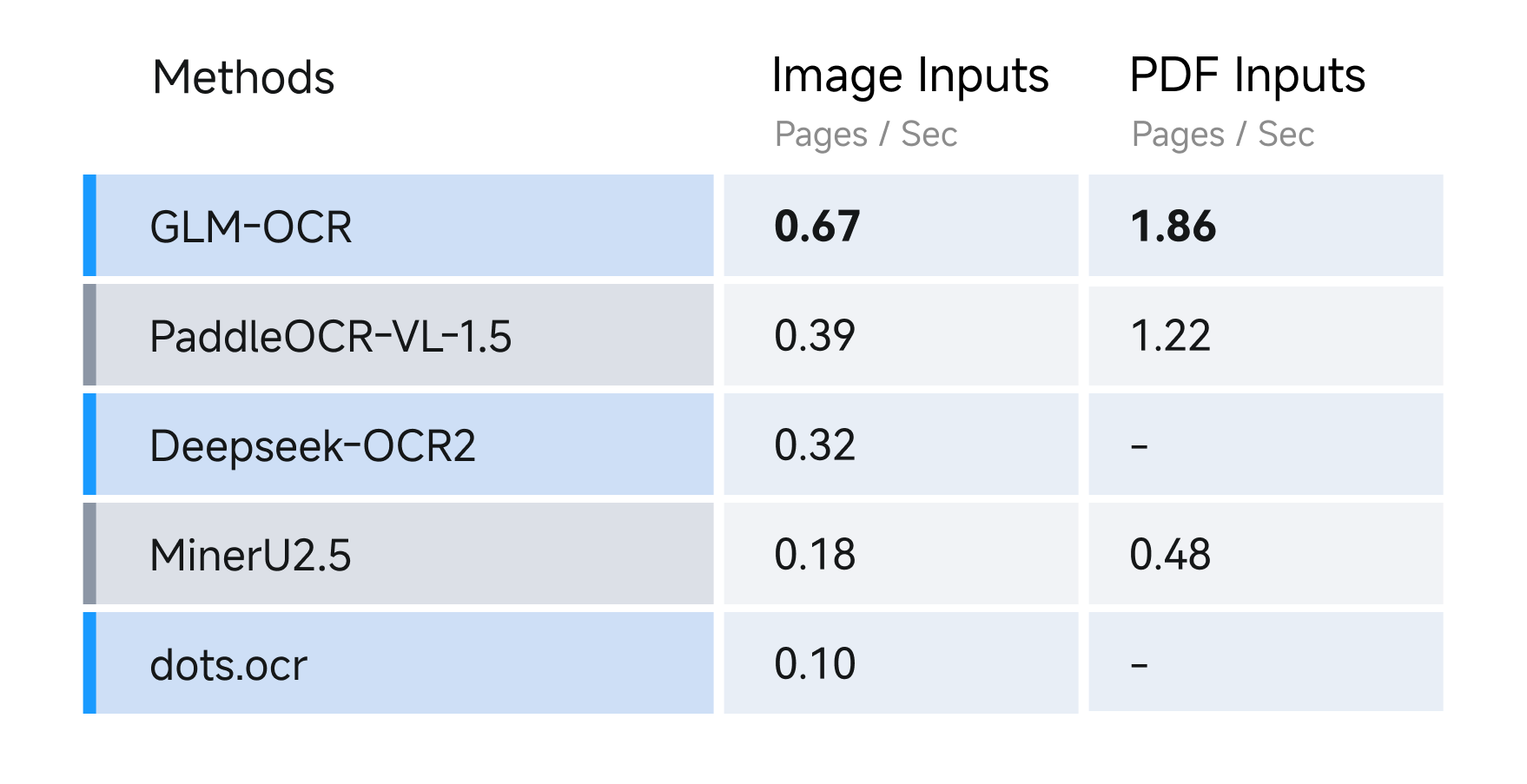 |
| 62 | |
| 63 | ## Usage |
| 64 | |
| 65 | ### Official SDK |
| 66 | |
| 67 | For document parsing tasks, we strongly recommend using our [official SDK](https://github.com/zai-org/GLM-OCR). |
| 68 | Compared with model-only inference, the SDK integrates PP-DocLayoutV3 and provides a complete, easy-to-use pipeline for document parsing, including layout analysis and structured output generation. This significantly reduces the engineering overhead required to build end-to-end document intelligence systems. |
| 69 | |
| 70 | Note that the SDK is currently designed for document parsing tasks only. For information extraction tasks, please refer to the following section and run inference directly with the model. |
| 71 | |
| 72 | ### vLLM |
| 73 | |
| 74 | 1. run |
| 75 | |
| 76 | ```bash |
| 77 | pip install -U vllm --extra-index-url https://wheels.vllm.ai/nightly |
| 78 | ``` |
| 79 | |
| 80 | or using docker with: |
| 81 | ``` |
| 82 | docker pull vllm/vllm-openai:nightly |
| 83 | ``` |
| 84 | |
| 85 | 2. run with: |
| 86 | |
| 87 | ```bash |
| 88 | pip install git+https://github.com/huggingface/transformers.git |
| 89 | vllm serve zai-org/GLM-OCR --allowed-local-media-path / --port 8080 |
| 90 | ``` |
| 91 | |
| 92 | ### SGLang |
| 93 | |
| 94 | |
| 95 | 1. using docker with: |
| 96 | |
| 97 | ```bash |
| 98 | docker pull lmsysorg/sglang:dev |
| 99 | ``` |
| 100 | |
| 101 | or build it from source with: |
| 102 | |
| 103 | ```bash |
| 104 | pip install git+https://github.com/sgl-project/sglang.git#subdirectory=python |
| 105 | ``` |
| 106 | |
| 107 | 2. run with: |
| 108 | |
| 109 | ```bash |
| 110 | pip install git+https://github.com/huggingface/transformers.git |
| 111 | python -m sglang.launch_server --model zai-org/GLM-OCR --port 8080 |
| 112 | ``` |
| 113 | |
| 114 | ### Ollama |
| 115 | |
| 116 | 1. Download [Ollama](https://ollama.com/download). |
| 117 | 2. run with: |
| 118 | |
| 119 | ```bash |
| 120 | ollama run glm-ocr |
| 121 | ``` |
| 122 | |
| 123 | Ollama will automatically use image file path when an image is dragged into the terminal: |
| 124 | |
| 125 | ```bash |
| 126 | ollama run glm-ocr Text Recognition: ./image.png |
| 127 | ``` |
| 128 | |
| 129 | ### Transformers |
| 130 | |
| 131 | ``` |
| 132 | pip install git+https://github.com/huggingface/transformers.git |
| 133 | ``` |
| 134 | |
| 135 | ```python |
| 136 | from transformers import AutoProcessor, AutoModelForImageTextToText |
| 137 | import torch |
| 138 | |
| 139 | MODEL_PATH = "zai-org/GLM-OCR" |
| 140 | messages = [ |
| 141 | { |
| 142 | "role": "user", |
| 143 | "content": [ |
| 144 | { |
| 145 | "type": "image", |
| 146 | "url": "test_image.png" |
| 147 | }, |
| 148 | { |
| 149 | "type": "text", |
| 150 | "text": "Text Recognition:" |
| 151 | } |
| 152 | ], |
| 153 | } |
| 154 | ] |
| 155 | processor = AutoProcessor.from_pretrained(MODEL_PATH) |
| 156 | model = AutoModelForImageTextToText.from_pretrained( |
| 157 | pretrained_model_name_or_path=MODEL_PATH, |
| 158 | torch_dtype="auto", |
| 159 | device_map="auto", |
| 160 | ) |
| 161 | inputs = processor.apply_chat_template( |
| 162 | messages, |
| 163 | tokenize=True, |
| 164 | add_generation_prompt=True, |
| 165 | return_dict=True, |
| 166 | return_tensors="pt" |
| 167 | ).to(model.device) |
| 168 | inputs.pop("token_type_ids", None) |
| 169 | generated_ids = model.generate(**inputs, max_new_tokens=8192) |
| 170 | output_text = processor.decode(generated_ids[0][inputs["input_ids"].shape[1]:], skip_special_tokens=False) |
| 171 | print(output_text) |
| 172 | ``` |
| 173 | |
| 174 | ### Prompt Limited |
| 175 | |
| 176 | GLM-OCR currently supports two types of prompt scenarios: |
| 177 | |
| 178 | 1. **Document Parsing** – extract raw content from documents. Supported tasks include: |
| 179 | |
| 180 | ```python |
| 181 | { |
| 182 | "text": "Text Recognition:", |
| 183 | "formula": "Formula Recognition:", |
| 184 | "table": "Table Recognition:" |
| 185 | } |
| 186 | ``` |
| 187 | |
| 188 | 2. **Information Extraction** – extract structured information from documents. Prompts must follow a strict JSON schema. For example, to extract personal ID information: |
| 189 | |
| 190 | ```python |
| 191 | 请按下列JSON格式输出图中信息: |
| 192 | { |
| 193 | "id_number": "", |
| 194 | "last_name": "", |
| 195 | "first_name": "", |
| 196 | "date_of_birth": "", |
| 197 | "address": { |
| 198 | "street": "", |
| 199 | "city": "", |
| 200 | "state": "", |
| 201 | "zip_code": "" |
| 202 | }, |
| 203 | "dates": { |
| 204 | "issue_date": "", |
| 205 | "expiration_date": "" |
| 206 | }, |
| 207 | "sex": "" |
| 208 | } |
| 209 | ``` |
| 210 | |
| 211 | ⚠️ Note: When using information extraction, the output must strictly adhere to the defined JSON schema to ensure downstream processing compatibility. |
| 212 | |
| 213 | ## Acknowledgement |
| 214 | |
| 215 | This project is inspired by the excellent work of the following projects and communities: |
| 216 | |
| 217 | - [PP-DocLayout-V3](https://huggingface.co/PaddlePaddle/PP-DocLayoutV3) |
| 218 | - [PaddleOCR](https://github.com/PaddlePaddle/PaddleOCR) |
| 219 | - [MinerU](https://github.com/opendatalab/MinerU) |
| 220 | |
| 221 | ## License |
| 222 | |
| 223 | The GLM-OCR model is released under the MIT License. |
| 224 | |
| 225 | The complete OCR pipeline integrates [PP-DocLayoutV3](https://huggingface.co/PaddlePaddle/PP-DocLayoutV3) for document layout analysis, which is licensed under the Apache License 2.0. Users should comply with both licenses when using this project. |
| 226 | |
| 227 | ## Citation |
| 228 | |
| 229 | If you find GLM-OCR useful in your research, please cite our technical report: |
| 230 | |
| 231 | ```bibtex |
| 232 | @misc{duan2026glmocrtechnicalreport, |
| 233 | title={GLM-OCR Technical Report}, |
| 234 | author={Shuaiqi Duan and Yadong Xue and Weihan Wang and Zhe Su and Huan Liu and Sheng Yang and Guobing Gan and Guo Wang and Zihan Wang and Shengdong Yan and Dexin Jin and Yuxuan Zhang and Guohong Wen and Yanfeng Wang and Yutao Zhang and Xiaohan Zhang and Wenyi Hong and Yukuo Cen and Da Yin and Bin Chen and Wenmeng Yu and Xiaotao Gu and Jie Tang}, |
| 235 | year={2026}, |
| 236 | eprint={2603.10910}, |
| 237 | archivePrefix={arXiv}, |
| 238 | primaryClass={cs.CL}, |
| 239 | url={https://arxiv.org/abs/2603.10910}, |
| 240 | } |
| 241 | ``` |
| 242 | |